
Deep Stable Learning for Cross-lingual Dependency Parsing
Paper info: Haijiang Liu, Chen Qiu, Qiyuan Li, Maofu Liu, Li Wang, and Jinguang Gu. 2025. Deep Stable Learning for Cross-lingual Dependency Parsing. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 24, 6, Article 56 (June 2025), 34 pages. https://doi.org/10.1145/3735509
I’m excited to share our latest research breakthrough in cross-lingual natural language processing, published in ACM Transactions on Asian and Low-Resource Language Information Processing. Our work addresses a fundamental challenge that has been limiting the effectiveness of dependency parsing across languages with different resource levels.
The Hidden Problem in Cross-Lingual Parsing
Cross-lingual dependency parsing (XDP) is crucial for understanding grammatical structures across multiple languages—a foundation for tasks like sentiment analysis and information extraction. However, we discovered a critical issue that previous research had overlooked: the out-of-distribution (OOD) problem caused by unbalanced sentence length distributions between high-resource languages (HRL) and low-resource languages (LRL).
What We Found
Through comprehensive analysis of the Universal Dependencies dataset spanning 43 languages across 22 language families, we uncovered that:
- HRL datasets (like Chinese) typically contain longer, more complex sentences with intricate dependency structures
- LRL datasets (like Cantonese) feature shorter sentences with simpler dependency patterns
- This imbalance causes models trained on HRLs to struggle when parsing LRL sentences, achieving only ~30% accuracy in zero-shot settings
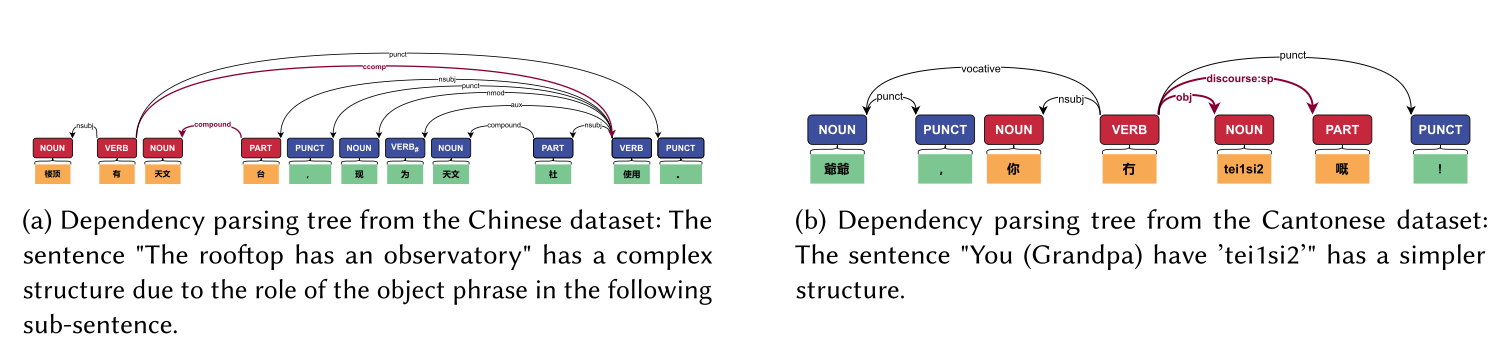
Figure 1: The demonstration of the OOD problem in Universal Dependency datasets. The Chinese example (top) shows complex dependency structures with multiple hierarchical relationships, while the Cantonese example (bottom) exhibits simpler, more direct dependencies. Both sentences express similar semantics (“A has B”) but with dramatically different structural complexity.
The core insight: sentence length directly correlates with dependency structure complexity. Longer sentences naturally contain more dependency relations and hierarchical relationships, making the parsing task fundamentally different between language types.
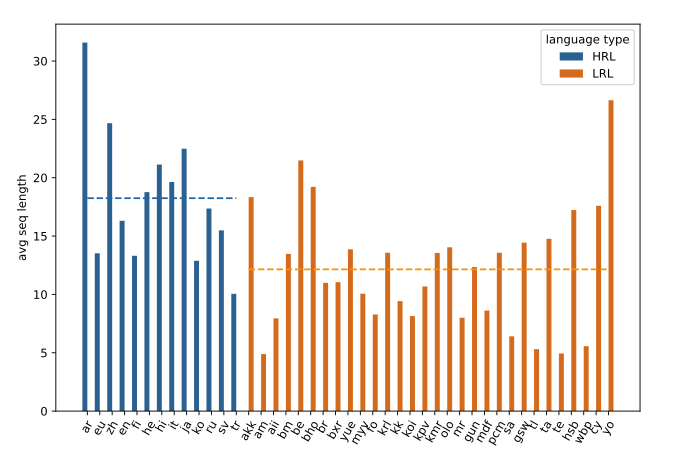
Figure 2: Average sentence length statistics across languages in Universal Dependencies v2.5. Blue bars represent HRL datasets, orange bars represent LRL datasets. The clear separation between the two groups (shown by the horizontal lines) demonstrates the systematic length imbalance that creates the OOD problem.
Our Solution: SL-XDP
We introduce SL-XDP (Stable Learning for Cross-lingual Dependency Parsing), a novel framework that tackles the OOD problem through two key innovations:
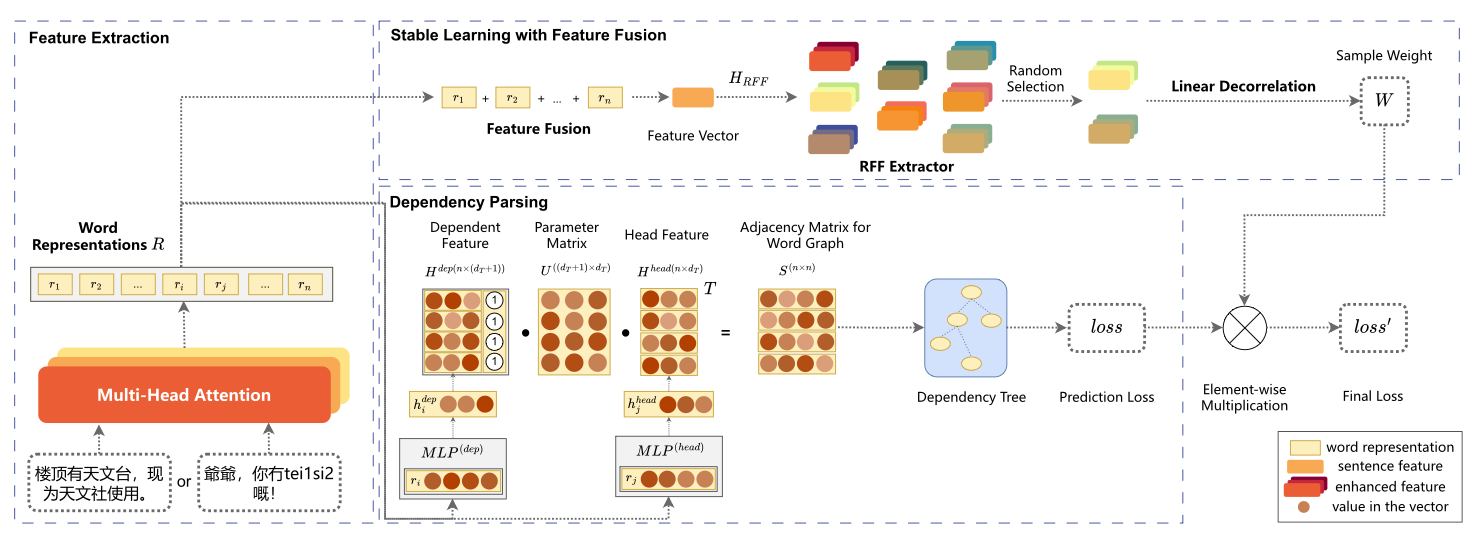
Figure 3: The general structure of our SL-XDP model consists of three integrated components: (1) Feature Extraction using multilingual pre-trained language models, (2) Dependency Parsing with biaffine attention networks, and (3) Deep Stable Learning with Feature Fusion module that learns adaptive sample weights to mitigate distributional shifts.
1. Feature Fusion Module
Rather than relying on generic sentence representations, we developed five specialized fusion operations to create comprehensive representations that capture dependency-specific information:
- Simple Add: Aggregates all token vectors while preserving information integrity
- Weighted Add: Uses BiLSTM to assign importance weights to different tokens
- Multi-Head Self-Attention: Leverages transformer attention for contextual relationships
- Attention-Free: Provides computational efficiency while maintaining long-term memory
- LAFF (Lightweight Attentional Feature Fusion): Offers parameter efficiency with focused representations
Our experiments showed that simple addition operations work best for dependency parsing, as they preserve crucial grammatical information without introducing noise.
2. Deep Stable Learning Algorithm
The core innovation lies in our application of deep stable learning to NLP. This algorithm:
- Eliminates correlations between sentence length and dependency predictions using Random Fourier Features (RFF) augmentation
- Learns adaptive sample weights to reduce the impact of distributional shifts
- Implements saving-reloading strategies to simulate global weight optimization during SGD training
The mathematical foundation ensures that our model focuses on genuine dependency relationships rather than spurious correlations with sentence length.
Impressive Results Across the Board
Universal Dependencies Performance
Our extensive evaluation on Universal Dependencies v2.5 demonstrates significant improvements:
- Average improvement of 1.6% over strong baselines like WAACL and MaChAmp
- Maximum improvement of 18% on specific languages (particularly Amharic)
- Consistent gains across 25 out of 30 low-resource languages
- Robust performance with both mBERT and XLM-R large backbones
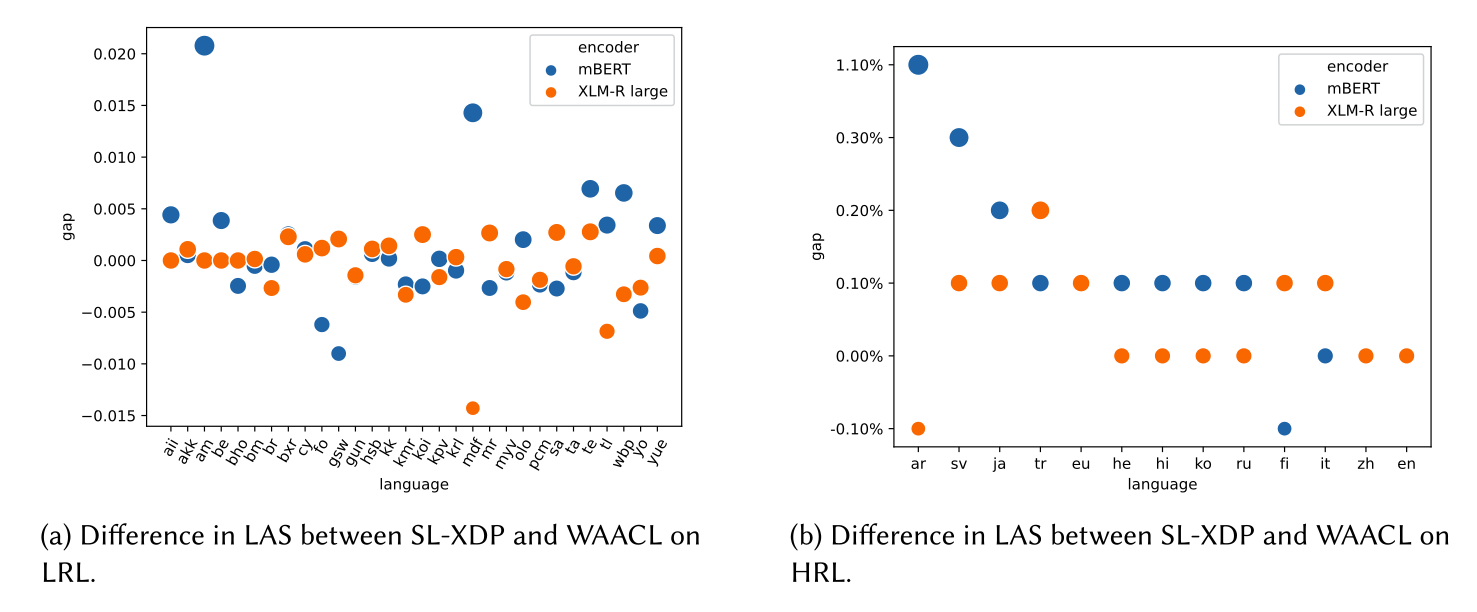
Figure 5: Language-by-language LAS differences between SL-XDP and WAACL baseline. Blue and orange nodes represent different PLM encoders (mBERT and XLM-R large). Positive values indicate improvements, with notable gains in languages like Amharic (am), Moksha (mdf), and Arabic (ar). The widespread distribution of positive improvements demonstrates SL-XDP’s broad effectiveness.
Language Family Analysis
The results reveal fascinating patterns:
- Seen language families benefit most from our approach (1.6% improvement with mBERT)
- Semitic languages within the Afro-Asiatic family show the highest gains (0.8% improvement)
- Morphologically complex languages demonstrate better transfer learning capabilities
Real-World Parsing Example
To illustrate the practical impact, consider this Cantonese parsing example:
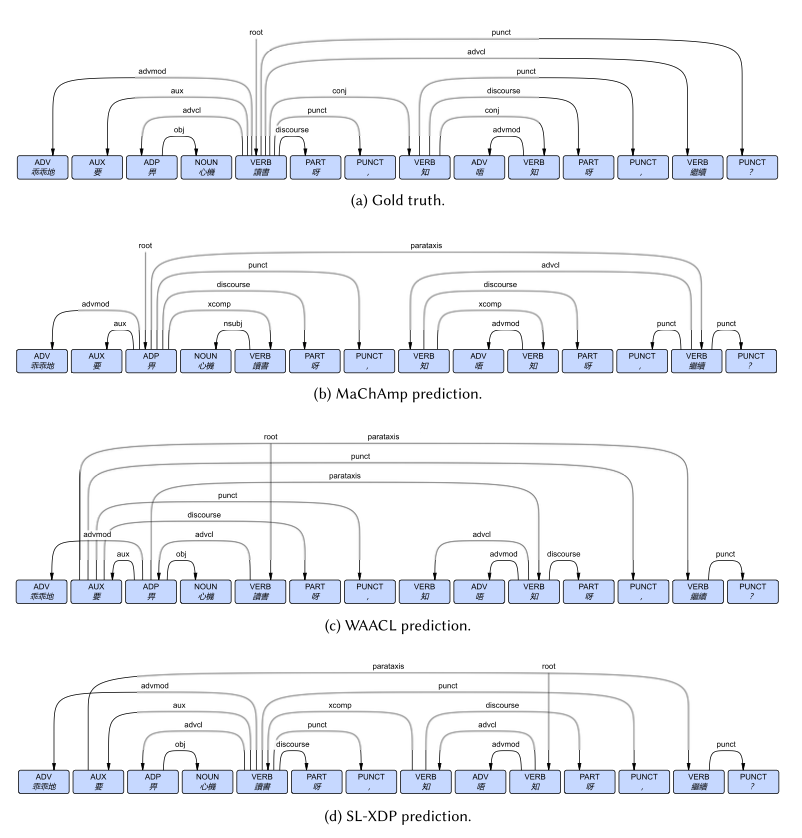
Figure 9: A concrete example of dependency parsing predictions on a Cantonese sentence meaning “Be obedient to study hard, (you) know, (can we) continue?” SL-XDP (bottom) correctly identifies most dependency relations including complex structures around punctuation, while baseline methods (MaChAmp and WAACL) make several critical errors in core dependencies.
Real-World Application: Named Entity Recognition
To validate practical applicability, we extended SL-XDP to multilingual NER on the WikiANN dataset:
- 88.05% average F1 score on training languages (vs. 37.24% for MaChAmp)
- 71.38% average F1 score on zero-shot languages (vs. 30.95% for MaChAmp)
- Exceptional zero-shot performance on languages like Bengali (83.62%) and Tagalog (82.49%)
Technical Innovation and Broader Impact
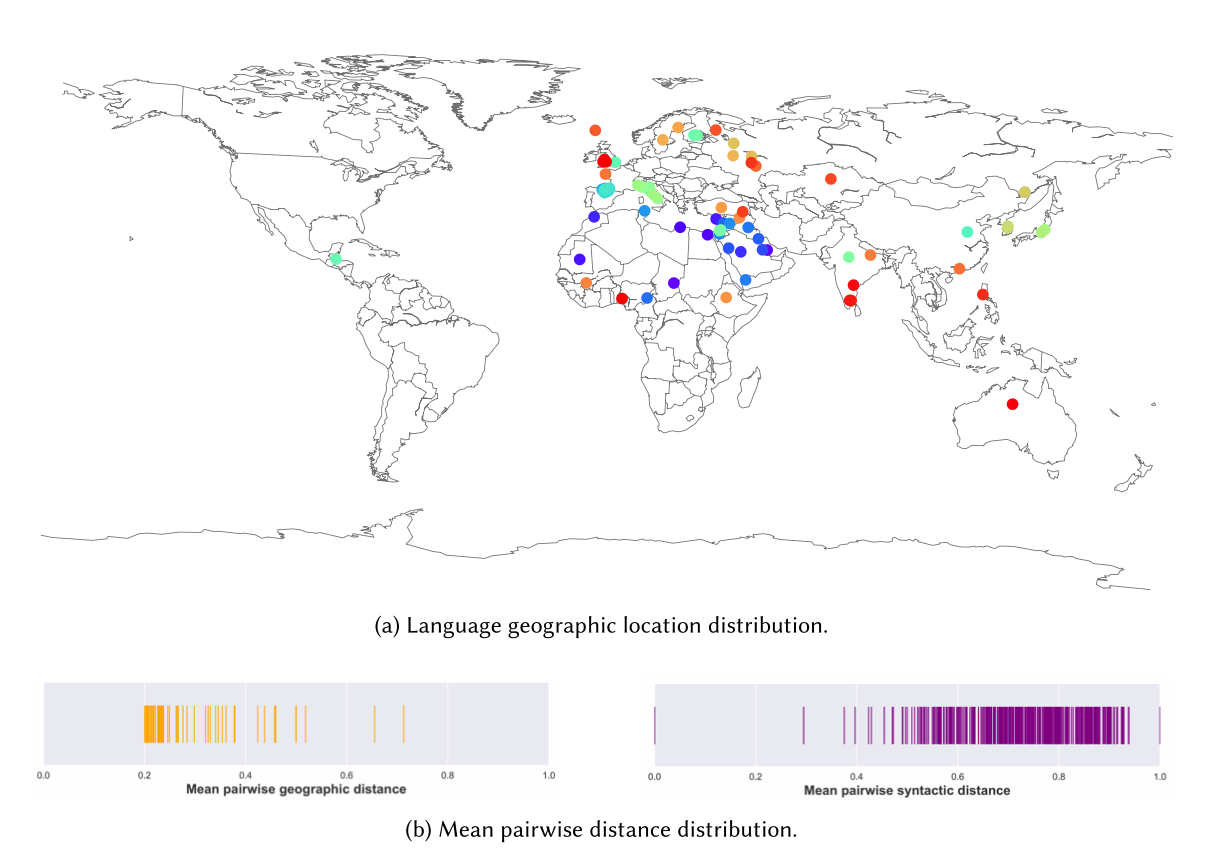
Figure 10: Language diversity analysis showing the geographic distribution and syntactic diversity of our experimental languages. Our chosen 43 languages span multiple continents and represent a wide range of syntactic features, ensuring robust evaluation across diverse linguistic contexts. The bottom panels show mean pairwise geographic and syntactic distance distributions, demonstrating comprehensive typological coverage.
Methodological Contributions
- First systematic analysis of the OOD problem in cross-lingual dependency parsing
- Novel application of deep stable learning to natural language understanding
- Comprehensive feature fusion framework specifically designed for parsing tasks
- Robust evaluation across 43 languages and multiple language families
Practical Implications
Our work enables:
- Enhanced information extraction systems that work reliably across languages
- Improved real-world NLP applications that handle diverse linguistic inputs
- Better support for low-resource languages in multilingual AI systems
- More robust cross-lingual transfer in scenarios with limited training data
Looking Forward
This research opens several exciting directions:
- Scaling to larger language models: Investigating how our approach performs with models like GPT and T5
- Morphological complexity: Exploring interactions between our method and rich morphological variations
- Interpretability: Making the deep stable learning decisions more transparent for linguistic analysis
- Resource optimization: Developing more efficient variants for deployment in resource-constrained environments
Why This Matters
Cross-lingual NLP is becoming increasingly important as AI systems need to serve diverse global populations. Our work addresses a fundamental barrier that has prevented effective transfer learning between high-resource and low-resource languages. By solving the OOD problem, we’re making multilingual AI more equitable and accessible.
The implications extend beyond dependency parsing—our deep stable learning framework could benefit other cross-lingual tasks facing similar distributional challenges, from machine translation to cross-lingual question answering.
Conclusion
SL-XDP represents a significant step forward in cross-lingual natural language processing. By identifying and addressing the root cause of poor transfer learning between languages with different resource levels, we’ve opened new possibilities for building truly multilingual AI systems.
Our comprehensive evaluation demonstrates that addressing distributional shifts through principled approaches like deep stable learning can yield substantial improvements across diverse linguistic contexts. This work not only advances the state-of-the-art in dependency parsing but also provides a blueprint for tackling similar challenges in other cross-lingual NLP tasks.
Citation:
1 | @article{10.1145/3735509, |
- Title: Deep Stable Learning for Cross-lingual Dependency Parsing
- Author: Haijiang LIU
- Created at : 2025-07-01 18:00:00
- Updated at : 2025-10-05 11:02:46
- Link: https://github.com/alexc-l/2025/07/01/sl-xdp/
- License: The ACM Digital Library is published by the Association for Computing Machinery. Copyright © 2025 ACM, Inc.