
Specializing Large Language Models to Simulate Survey Response Distributions for Global Populations
Paper info: Yong Cao, Haijiang Liu, Arnav Arora, Isabelle Augenstein, Paul Röttger, Daniel Hershcovich. 2025. Specializing Large Language Models to Simulate Survey Response Distributions for Global Populations. 2025 Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics.
I’m excited to share our latest publication, “Specializing Large Language Models to Simulate Survey Response Distributions for Global Populations,” which will be presented at NAACL 2025. This work represents a significant step forward in using AI to understand and predict cultural survey responses across diverse global populations.
Before we begin - Key Findings
Our experiments with seven different LLMs across three model families demonstrated several important findings:
- Significant Improvement Over Zero-Shot: Our fine-tuning method substantially outperforms zero-shot prompting and other baseline methods, even on unseen questions, countries, and completely new surveys.
- Generalization Capability: The specialized models show improved performance on both seen and unseen countries and questions, demonstrating their ability to generalize beyond the training data.
- Cultural Sensitivity: The fine-tuned models become more sensitive to cultural contexts, producing more diverse and context-appropriate response distributions.
- Language Robustness: We found limited sensitivity to language differences in this task, suggesting our approach works across different languages.
The Problem We’re Solving
Large-scale surveys are essential tools for social science research and policy making, but they’re expensive and time-consuming to conduct. Imagine if we could accurately simulate how different populations would respond to survey questions without actually fielding the surveys. This capability could accelerate social science research and inform better policy decisions.
Previous work has explored using large language models (LLMs) for simulating human behaviors, mostly through prompting strategies. However, these approaches often generate stereotypical or overconfident answers, especially in culturally diverse contexts, limiting their usefulness for survey simulations.
Cultural Survey Simulation Dataset
In our paper, we constructed a comprehensive Cultural Survey Simulation Dataset to train and evaluate our specialized large language models (LLMs) for survey response distribution simulation. Here are the key details about the dataset construction:
Data Sources
Our primary data source was the 2017-2022 wave of the World Values Survey (WVS), which is one of the most extensive and widely-used cross-national surveys of human values and beliefs. The WVS covers 66 countries with over 80,000 respondents, capturing societal attitudes across various cultural dimensions including family, regional values, education, moral principles, corruption, and accountability.
Data Processing
We processed the raw WVS data to create a structured dataset suitable for training our models:
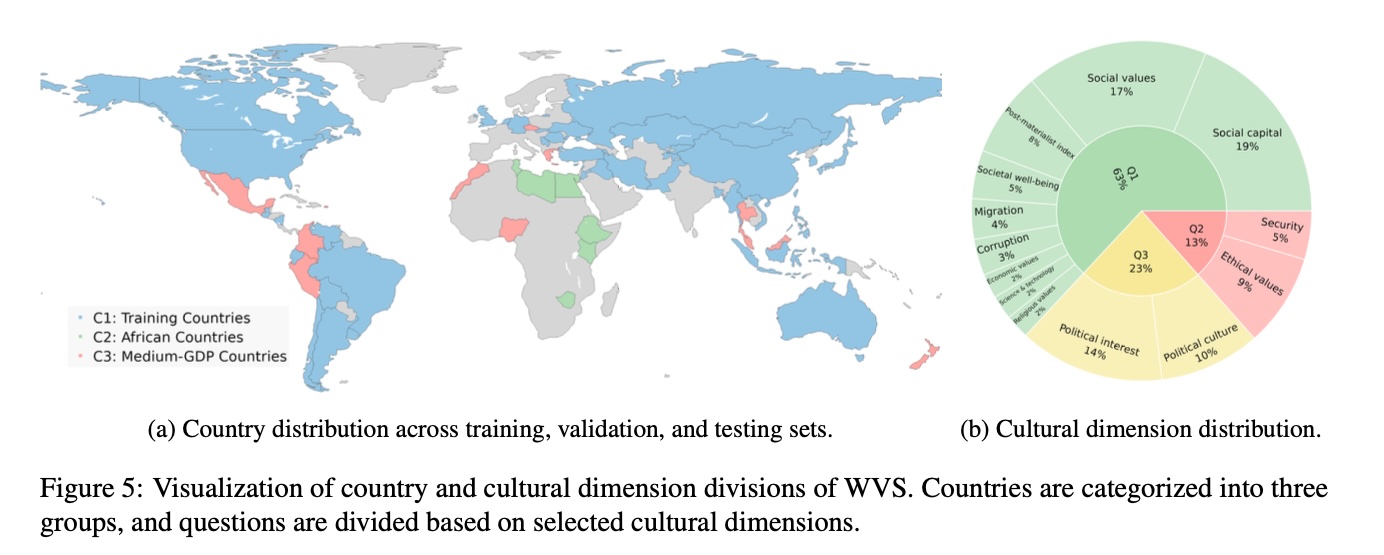
Country Selection: We included all countries with more than 1,000 respondents to ensure robust cross-cultural representation, resulting in a set of 65 countries (Northern Ireland was excluded due to insufficient sample size).
Question Selection: We used the original survey questions and answers, excluding validity-check options such as “not applicable” and “refuse to answer” that rarely appeared in human-collected responses.
Language Versions: We created both English and Chinese versions of the dataset using the official translations from the WVS source. For the Chinese questionnaire, we used GLM-4 to translate missing questions.
Dataset Splits
To evaluate model performance across different scenarios, we created multiple splits of the data:
Question Splits:
: Questions 1-163 (150 questions) : Questions 164-198 (35 questions about religious and ethical values) : Questions 199-259 (59 questions about political interest and culture)
Country Splits:
: All WVS countries not in or (46 countries) : African countries surveyed (8 countries: Egypt, Ethiopia, Kenya, Libya, Morocco, Nigeria, Tunisia, Zimbabwe) : Medium-GDP countries sampled from each continent (11 countries: Malaysia, Thailand, Czechia, Greece, Nigeria, Morocco, Peru, Colombia, Mexico, Puerto Rico, New Zealand)
Training/Validation/Test Sets:
- We divided the data into training, validation, and test sets based on the question and country splits.
- The test set includes five subsets designed to evaluate performance on unseen value questions, unseen regional countries, and representative medium-GDP countries.
Unseen Survey Dataset
To evaluate generalization to completely new surveys, we used an additional subset from the GlobalOpinionQA project - the Pew Global Attitudes Survey. This survey maintains a similar format to the WVS but includes different cultural questions. We compiled two sets of countries for this test set:
: Ten randomly sampled countries from : The same medium-GDP countries as in the WVS split
Cultural Dimensions
The questions in our dataset cover a wide range of cultural dimensions:
- Social values, attitudes, and stereotypes
- Societal well-being
- Social capital, trust, and organizational membership
- Economic values
- Corruption
- Migration
- Post-materialist index
- Science and technology
- Religious values
- Security
- Ethical values and norms
- Political interest and participation
- Political culture and regimes
Dataset Statistics
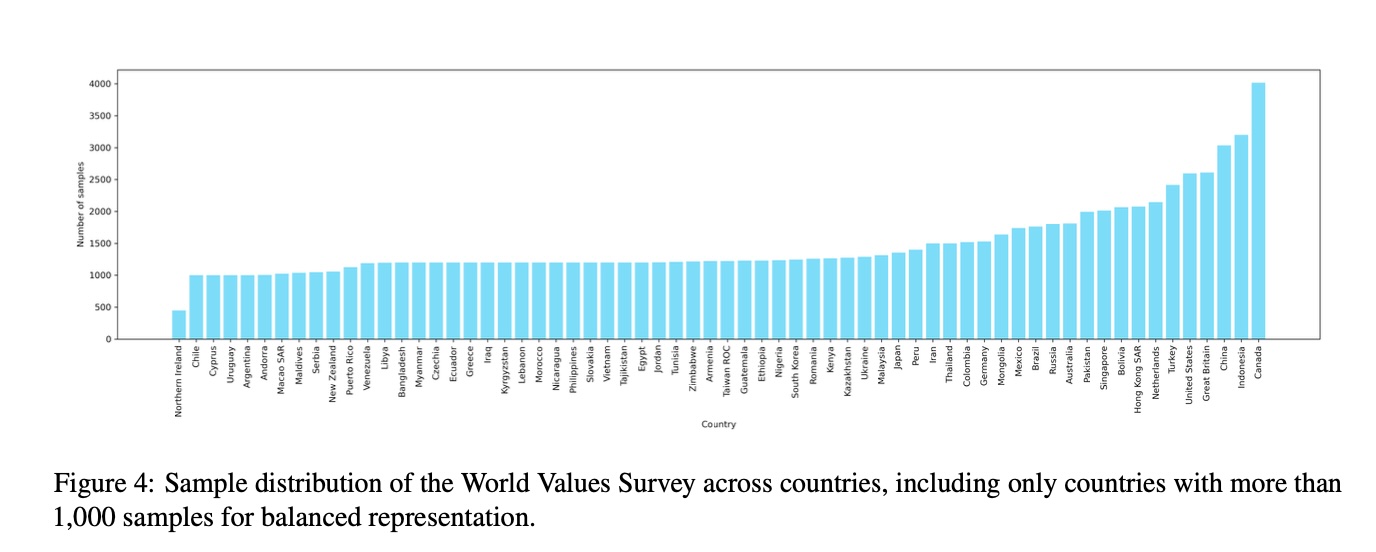
Our final dataset includes:
- 65 countries with robust sample sizes
- 259 questions covering diverse cultural dimensions
- Response distributions for each question-country pair
- Both English and Chinese language versions
This comprehensive dataset allows us to train and evaluate models on their ability to simulate survey response distributions across diverse cultural contexts and languages.
For more details about the dataset construction and access to the dataset itself, please visit our GitHub repository.
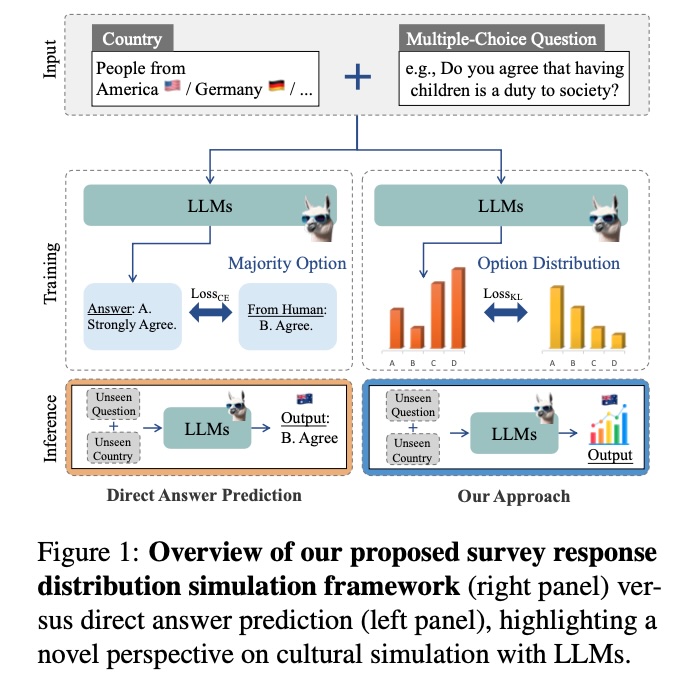
Our Approach: First-Token Probability Alignment
In our research, we introduce a novel framework for specializing large language models (LLMs) to simulate survey response distributions across diverse cultural contexts. The core of our approach is the First-Token Probability Alignment method, which is designed to improve the models’ ability to predict response distributions rather than just single answers.
Probability Distribution Simulation
Unlike most existing studies that directly prompt LLMs with multiple-choice questions to assess their cultural knowledge or behavior, our task focuses on simulating the distribution of response options for given questions rather than predicting single answers. Specifically, let
First-Token Probability Alignment
Our method leverages the first token of each question’s corresponding options as the target for alignment. The processed question Q is used as input into LLMs. The model outputs logits
For the training optimization objective, we employ Kullback-Leibler Divergence loss (
Where
To improve the efficiency of the fine-tuning process, we implement Low-Rank Adaptation (LoRA), a parameter-efficient method specifically designed for optimizing LLMs. This approach allows us to fine-tune large models without requiring excessive computational resources.
Implementation Details
Our training setup includes:
- AdamW optimizer with a learning rate of 1e-4
- Fully Sharded Data Parallel along with a mixed precision strategy to enhance computational efficiency
- LoRA with a rank of 8, a scaling factor lora_alpha set to 32, and a dropout rate of 0.05
We train on a single A100 GPU with a batch size of 16 for Llama3 and Vicuna1.5-7B, and 4 for Vicuna1.5-13B.
The training process involves presenting the model with questions and options, and adjusting the model’s parameters to minimize the divergence between its predicted response distributions and the actual human survey data. This specialized training enables the model to better capture the nuanced patterns in how different cultural groups respond to survey questions.
By focusing on aligning the first-token probabilities, our method ensures that the model learns to distribute probability mass across response options in a way that reflects real-world cultural variations. This approach has proven to be significantly more effective than zero-shot prompting and other baseline methods in our experiments.
Experimental Setup
Our experimental setup was designed to rigorously evaluate the effectiveness of our fine-tuning method for specializing LLMs in survey response distribution simulation. Here are the key details:
Models Evaluated:
We tested seven different models across three model families to ensure our findings were generalizable:
- Vicuna1.5 (7B and 13B parameter versions)
- Llama3 (8B Base and Instruct versions)
- Deepseek-Distilled-Qwen (7B, 14B, and 32B)
Baselines:
To establish performance benchmarks, we compared our fine-tuning approach against several baselines:
- Zero-shot prompting (ZS): Directly querying models with country context and questions
- Control setting ([ctrl]): Replacing countries in queries with randomly selected countries
- K-Nearest Neighbors (KNN): Using BERT embeddings to find most similar training examples
- Avg_Culture: Using mean option distribution across training countries
- JSON-ZS: Prompting models to generate option distributions in JSON format without fine-tuning
Evaluation Metrics:
We used two primary metrics to assess model performance:
- Jensen-Shannon Divergence (1−JSD): Measures similarity between predicted and actual distributions (higher values indicate greater similarity)
- Earth Mover Distance (EMD): Quantifies work required to transform one distribution into another (lower values indicate greater similarity)
Results
Our results demonstrated the effectiveness of our approach across multiple dimensions:
Main Findings:
- Our fine-tuning method significantly improved prediction accuracy compared to zero-shot methods across all model sizes and types
- Fine-tuned models generalized well to unseen countries, questions, and even completely new surveys
- Performance improvements were consistent across different model architectures and sizes
- The models showed increased cultural sensitivity and diversity in predictions after fine-tuning
Generalization Performance:
- Fine-tuned models showed substantial improvements in both 1−JSD and EMD scores compared to zero-shot models
- Unseen questions presented a greater challenge than unseen countries, indicating questions may require more nuanced cultural understanding
- Llama3-Instruct models demonstrated particular robustness across African countries, maintaining higher accuracy levels
Variation Sensitivity:
- Fine-tuned models were more sensitive to country context than zero-shot models
- The models showed improved ability to capture cultural nuances during training
- Diversity in model outputs increased after fine-tuning, with responses becoming more responsive to diverse cultural contexts
Robustness Analysis:
- Limited sensitivity to language differences was observed, suggesting our approach works across different languages
- Models generalized well to new surveys (Pew dataset), with significant performance improvements after fine-tuning
- Performance improvements were consistent across different model sizes
Implications
This research demonstrates the potential of specialized LLMs to simulate survey response distributions, which could revolutionize how social scientists conduct research and how policymakers make decisions. By reducing the need for expensive and time-consuming surveys, we can accelerate the pace of social science research and improve the accuracy of policy decisions.
However, our results also highlight important limitations. Even our best models struggle with unseen questions and exhibit less diversity in predictions compared to human survey data. This suggests there’s still work to be done to fully capture the complexity of human cultural responses.
Future Work
Looking forward, we plan to:
- Explore broader language coverage to enhance cross-linguistic robustness
- Investigate whether our fine-tuning approach results in less biased models for general-purpose applications
- Experiment with even larger models to better understand their capabilities in simulating cultural diversity
Conclusion
This work represents an important step toward creating more culturally aware AI systems that can accurately simulate human responses across diverse global populations. While we’ve made significant progress, our results also serve as a cautionary note about the current limitations of LLMs for this task. As we continue to improve these models, we must remain mindful of their ethical implications and potential for misuse.
You can find the full paper on arXiv.
Citation:
1 | @misc{cao2025specializinglargelanguagemodels, |
- Title: Specializing Large Language Models to Simulate Survey Response Distributions for Global Populations
- Author: Haijiang LIU
- Created at : 2025-03-21 19:17:20
- Updated at : 2025-10-05 11:01:03
- Link: https://github.com/alexc-l/2025/03/21/1st-align/
- License: © 2025 NAACL. All rights are reserved, including those for text and data mining, AI training, and similar technologies.